Getting started¶
Spidermon is a monitoring tool for Scrapy spiders that allows you to write monitors that may validate the execution and the results of your spiders.
This tutorial shows how to set up Spidermon to monitor a spider to check if it extracted a minimum number of items and if they follow a defined data model. The results of the spider execution will be sent to a Slack channel.
It is expected that you have a basic knowledge of Scrapy. If that is not the case read the Scrapy Tutorial and come back later. We will also assume that Spidermon is already installed on your system. If that is not the case case, see Installation.
Our sample project¶
You can find the complete code of our tutorial project here.
We are going to scrape quotes.toscrape.com, a website that lists quotes from famous authors. First we need a regular Scrapy project and create a simple spider:
$ scrapy startproject tutorial
$ cd tutorial
$ scrapy genspider quotes quotes.toscrape.com
And our spider code:
# tutorial/spiders/quotes.py
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ["http://quotes.toscrape.com/"]
def parse(self, response):
for quote in response.css(".quote"):
yield {
"quote": quote.css(".text::text").get(),
"author": quote.css(".author::text").get(),
"author_url": response.urljoin(
quote.css(".author a::attr(href)").get()
),
"tags": quote.css(".tag *::text").getall(),
}
yield scrapy.Request(
response.urljoin(response.css(".next a::attr(href)").get())
)
Enabling Spidermon¶
To enable Spidermon in your project, include the following lines in your Scrapy project settings.py file:
SPIDERMON_ENABLED = True
EXTENSIONS = {
"spidermon.contrib.scrapy.extensions.Spidermon": 500,
}
Our first monitor¶
Monitors are similar to test cases with a set of methods that are executed at well defined moments of the spider execution containing your monitoring logic.
Monitors must be grouped into monitor suites which define a list of monitors that need to be executed and the actions to be performed before and after the suite execute all monitors.
Our first monitor will check whether at least 10 items were returned at the end of the spider execution.
Create a new file called monitors.py that will contain the definition and configuration of your monitors.
# tutorial/monitors.py
from spidermon import Monitor, MonitorSuite, monitors
@monitors.name("Item count")
class ItemCountMonitor(Monitor):
@monitors.name("Minimum number of items")
def test_minimum_number_of_items(self):
item_extracted = getattr(self.data.stats, "item_scraped_count", 0)
minimum_threshold = 10
msg = "Extracted less than {} items".format(minimum_threshold)
self.assertTrue(item_extracted >= minimum_threshold, msg=msg)
class SpiderCloseMonitorSuite(MonitorSuite):
monitors = [
ItemCountMonitor,
]
This suite needs to be executed when the spider closes, so we include it in the SPIDERMON_SPIDER_CLOSE_MONITORS list in your settings.py file:
# tutorial/settings.py
SPIDERMON_SPIDER_CLOSE_MONITORS = ("tutorial.monitors.SpiderCloseMonitorSuite",)
After executing the spider, you should see the following in your logs:
$ scrapy crawl quotes
(...)
INFO: [Spidermon] -------------------- MONITORS --------------------
INFO: [Spidermon] Item count/Minimum number of items... OK
INFO: [Spidermon] --------------------------------------------------
INFO: [Spidermon] 1 monitor in 0.001s
INFO: [Spidermon] OK
INFO: [Spidermon] ---------------- FINISHED ACTIONS ----------------
INFO: [Spidermon] --------------------------------------------------
INFO: [Spidermon] 0 actions in 0.000s
INFO: [Spidermon] OK
INFO: [Spidermon] ----------------- PASSED ACTIONS -----------------
INFO: [Spidermon] --------------------------------------------------
INFO: [Spidermon] 0 actions in 0.000s
INFO: [Spidermon] OK
INFO: [Spidermon] ----------------- FAILED ACTIONS -----------------
INFO: [Spidermon] --------------------------------------------------
INFO: [Spidermon] 0 actions in 0.000s
INFO: [Spidermon] OK
[scrapy.statscollectors] INFO: Dumping Scrapy stats:
(...)
If the condition in your monitor fails, this information will appear in the logs:
$ scrapy crawl quotes
(...)
INFO: [Spidermon] -------------------- MONITORS --------------------
INFO: [Spidermon] Item count/Minimum number of items... FAIL
INFO: [Spidermon] --------------------------------------------------
ERROR: [Spidermon]
====================================================================
FAIL: Item count/Minimum number of items
--------------------------------------------------------------------
Traceback (most recent call last):
File "/tutorial/monitors.py",
line 17, in test_minimum_number_of_items
item_extracted >= minimum_threshold, msg=msg
AssertionError: False is not true : Extracted less than 10 items
INFO: [Spidermon] 1 monitor in 0.001s
INFO: [Spidermon] FAILED (failures=1)
INFO: [Spidermon] ---------------- FINISHED ACTIONS ----------------
INFO: [Spidermon] --------------------------------------------------
INFO: [Spidermon] 0 actions in 0.000s
INFO: [Spidermon] OK
INFO: [Spidermon] ----------------- PASSED ACTIONS -----------------
INFO: [Spidermon] --------------------------------------------------
INFO: [Spidermon] 0 actions in 0.000s
INFO: [Spidermon] OK
INFO: [Spidermon] ----------------- FAILED ACTIONS -----------------
INFO: [Spidermon] --------------------------------------------------
INFO: [Spidermon] 0 actions in 0.000s
INFO: [Spidermon] OK
Notifications¶
Receiving fail notification in the logs may be helpful during the development but not so useful when you are running a huge number of spiders, so you can define actions to be performed when your spider start or finishes (with or without failures).
Spidermon has some built-in actions but you are free to define your own.
Slack notifications¶
Here we will configure a built-in Spidermon action that sends a pre-defined message to a Slack channel using a bot when a monitor fails.
# tutorial/monitors.py
from spidermon.contrib.actions.slack.notifiers import SendSlackMessageSpiderFinished
# (...your monitors code...)
class SpiderCloseMonitorSuite(MonitorSuite):
monitors = [
ItemCountMonitor,
]
monitors_failed_actions = [
SendSlackMessageSpiderFinished,
]
After enabling the action, you need to provide the Slack credentials. You can access the required credentials by following these steps to How do I configure a Slack bot for Spidermon?. Later, fill the credentials in your settings.py as follows:
# tutorial/settings.py
(...)
SPIDERMON_SLACK_SENDER_TOKEN = "<SLACK_SENDER_TOKEN>"
SPIDERMON_SLACK_SENDER_NAME = "<SLACK_SENDER_NAME>"
SPIDERMON_SLACK_RECIPIENTS = ["@yourself", "#yourprojectchannel"]
If a monitor fails, the recipients provided will receive a message in Slack:

Telegram notifications¶
Here we will configure a built-in Spidermon action that sends a pre-defined message to a Telegram user, group or channel using a bot when a monitor fails.
# tutorial/monitors.py
from spidermon.contrib.actions.telegram.notifiers import (
SendTelegramMessageSpiderFinished,
)
# (...your monitors code...)
class SpiderCloseMonitorSuite(MonitorSuite):
monitors = [
ItemCountMonitor,
]
monitors_failed_actions = [
SendTelegramMessageSpiderFinished,
]
After enabling the action, you need to provide the Telegram bot token and Recipients. You can learn more about how to create and configure a bot by following the steps on How do I configure a Telegram bot for Spidermon?. Later, fill the required information in your settings.py as follows:
# tutorial/settings.py
(...)
SPIDERMON_TELEGRAM_SENDER_TOKEN = "<TELEGRAM_SENDER_TOKEN>"
SPIDERMON_TELEGRAM_RECIPIENTS = ["chatid", "groupid", "@channelname"]
If a monitor fails, the recipients provided will receive a message in Telegram:
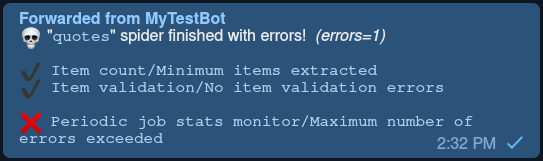
Discord notifications¶
Here we will configure a built-in Spidermon action that sends a pre-defined message to a Discord channel using a bot when a monitor fails.
# tutorial/monitors.py
from spidermon.contrib.actions.discord.notifiers import SendDiscordMessageSpiderFinished
# (...your monitors code...)
class SpiderCloseMonitorSuite(MonitorSuite):
monitors = [
ItemCountMonitor,
]
monitors_failed_actions = [
SendDiscordMessageSpiderFinished,
]
After enabling the action, you need to provide the Discord Webhook URL. You can learn more about how to create and configure a webhook How do I configure a Discord bot for Spidermon?. Later, fill the required information in your settings.py as follows:
# tutorial/settings.py
(...)
SPIDERMON_DISCORD_WEBHOOK_URL = "<DISCORD_WEBHOOK_URL>"
If a monitor fails, the recipients provided will receive a message in Discord:
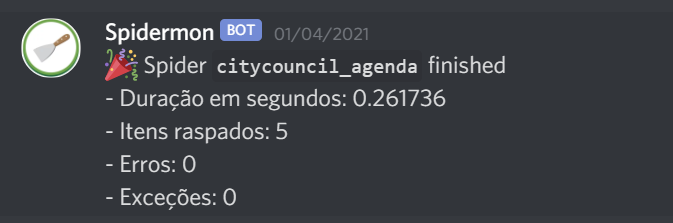
The target channel is configured during the webhook creation on Discord.
In case you want to see the messages only in the terminal, set as True the environment variable SPIDERMON_DISCORD_FAKE.
Item validation¶
Item validators allows you to match your returned items with predetermined structure ensuring that all fields contains data in the expected format. supports JSON Schema to define the structure of your item.
First step is to change our actual spider code to use Scrapy items. Create a new file called items.py:
# tutorial/items.py
import scrapy
class QuoteItem(scrapy.Item):
quote = scrapy.Field()
author = scrapy.Field()
author_url = scrapy.Field()
tags = scrapy.Field()
And then modify the spider code to use the newly defined item:
# tutorial/spiders/quotes.py
import scrapy
from tutorial.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ["http://quotes.toscrape.com/"]
def parse(self, response):
for quote in response.css(".quote"):
item = QuoteItem(
quote=quote.css(".text::text").get(),
author=quote.css(".author::text").get(),
author_url=response.urljoin(quote.css(".author a::attr(href)").get()),
tags=quote.css(".tag *::text").getall(),
)
yield item
yield scrapy.Request(
response.urljoin(response.css(".next a::attr(href)").get())
)
Now we need to create our jsonschema model in the schemas/quote_item.json file that will contain all the validation rules:
{
"$schema": "http://json-schema.org/draft-07/schema",
"type": "object",
"properties": {
"quote": {
"type": "string"
},
"author": {
"type": "string"
},
"author_url": {
"type": "string",
"pattern": ""
},
"tags": {
"type": "array",
"items": {
"type":"string"
}
}
},
"required": [
"quote",
"author",
"author_url"
]
}
To allow Spidermon to validate your items, you need to include an item pipeline and inform the path of the json schema used for validation:
# tutorial/settings.py
ITEM_PIPELINES = {
"spidermon.contrib.scrapy.pipelines.ItemValidationPipeline": 800,
}
SPIDERMON_VALIDATION_SCHEMAS = ("./schemas/quote_item.json",)
After that, every time you run your spider you will have a new set of stats in your spider log providing information about the results of the validations:
$ scrapy crawl quotes
(...)
'spidermon/validation/fields': 400,
'spidermon/validation/items': 100,
'spidermon/validation/validators': 1,
'spidermon/validation/validators/item/jsonschema': True,
[scrapy.core.engine] INFO: Spider closed (finished)
You can then create a new monitor that will check these new statistics and raise a failure when we have a item validation error:
# monitors.py
from spidermon.contrib.monitors.mixins import StatsMonitorMixin
# (...other monitors...)
@monitors.name("Item validation")
class ItemValidationMonitor(Monitor, StatsMonitorMixin):
@monitors.name("No item validation errors")
def test_no_item_validation_errors(self):
validation_errors = getattr(self.stats, "spidermon/validation/fields/errors", 0)
self.assertEqual(
validation_errors,
0,
msg="Found validation errors in {} fields".format(validation_errors),
)
class SpiderCloseMonitorSuite(MonitorSuite):
monitors = [
ItemCountMonitor,
ItemValidationMonitor,
]
monitors_failed_actions = [
SendSlackMessageSpiderFinished,
]
You could also set the pipeline to include the validation error as a field in the item (although it may not be necessary, since the validation errors are included in the crawling stats and your monitor can check them once the spiders finishes):
By default, it adds a field called _validation to the item when the item doesn’t match the schema:
# tutorial/settings.py
SPIDERMON_VALIDATION_ADD_ERRORS_TO_ITEMS = True
The resulted item will look like this:
{
'_validation': {'author_url': ['Invalid URL']},
'author': 'Mark Twain',
'author_url': 'not_a_valid_url',
'quote': 'Never tell the truth to people who are not worthy of it.',
'tags': ['truth']
}